practicaDatos
Ejemplo 2 Web Scraping
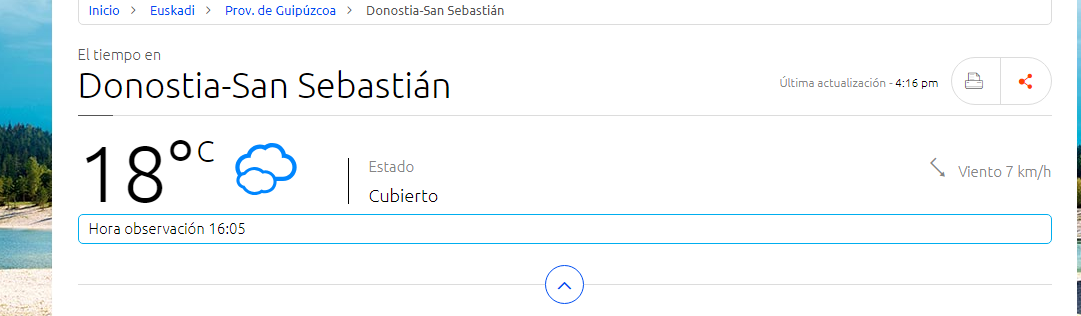
Web scraping con Python: Se desea obtener la temperatura actual en Donostia y guardar dicho dato en formato texto Para ello abrir Python y escribir línea por línea lo siguiente:
>>import requests
>>from bs4 import BeautifulSoup
>>page=requests.get("https://www.eltiempo.es/donostia-san-sebastian.html")
>>soup=BeautifulSoup(page.content,'html.parser')
>>seven_day=soup.find(id="topHeader")
>>forecast_items=seven_day.find_all(class_="m_tables_top_temp")
>>tonight=forecast_items[0]
>>print(tonight.prettify())
Aparecerá todo el código del que interesa obtener los datos:
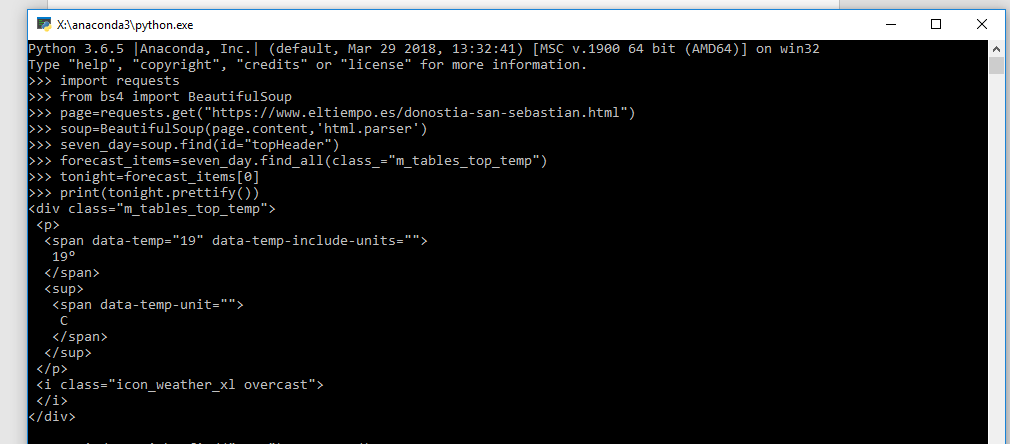 Añadir las siguientes líneas:
Añadir las siguientes líneas:
>>period1=tonight.find("span").get_text()
>>period2=tonight.find("sup").get_text()
>>print(period1)
>>print(period2)
Se verá en pantalla los datos que se buscan:
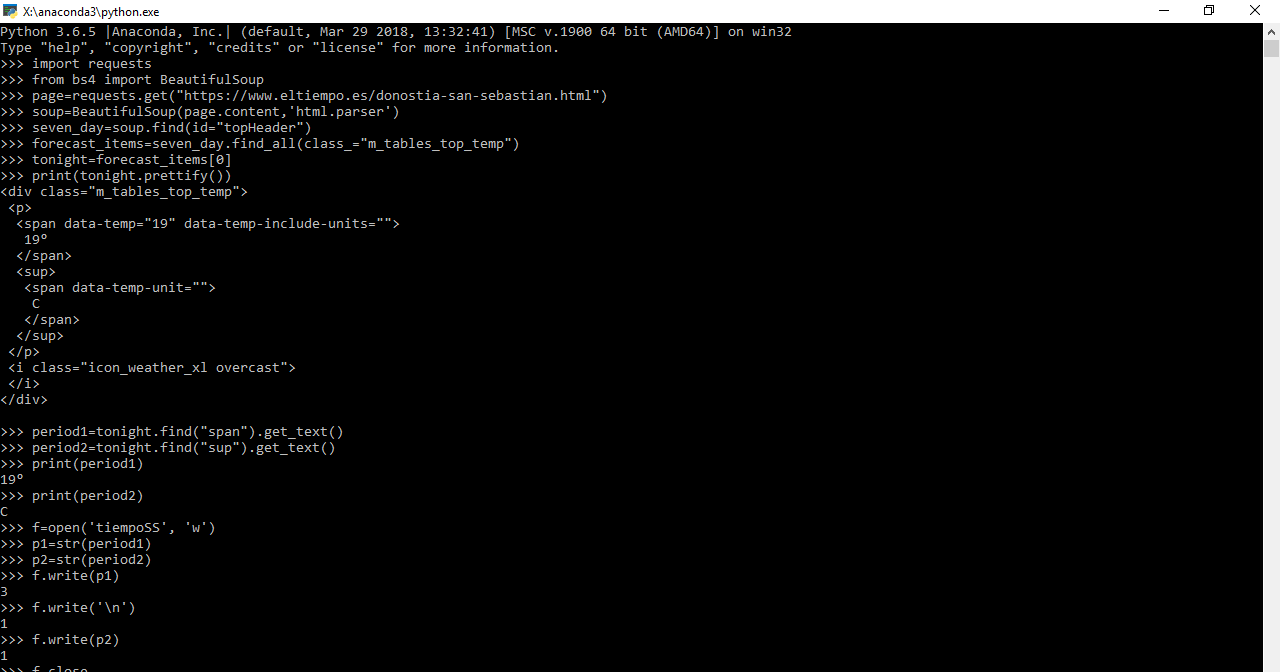 Añadir las siguientes líneas:
Añadir las siguientes líneas:
>>f=open('tiempoSS', 'w')
>>p1=str(period1)
>>p2=str(period2)
>>f.write(p1)
Aparecerá el número de caracteres que se han escrito en el documento generado:
Añadir las siguientes líneas:
>>f.write('\n')
>>f.write(p2)
>>f.close()
El codigo al completo será así:
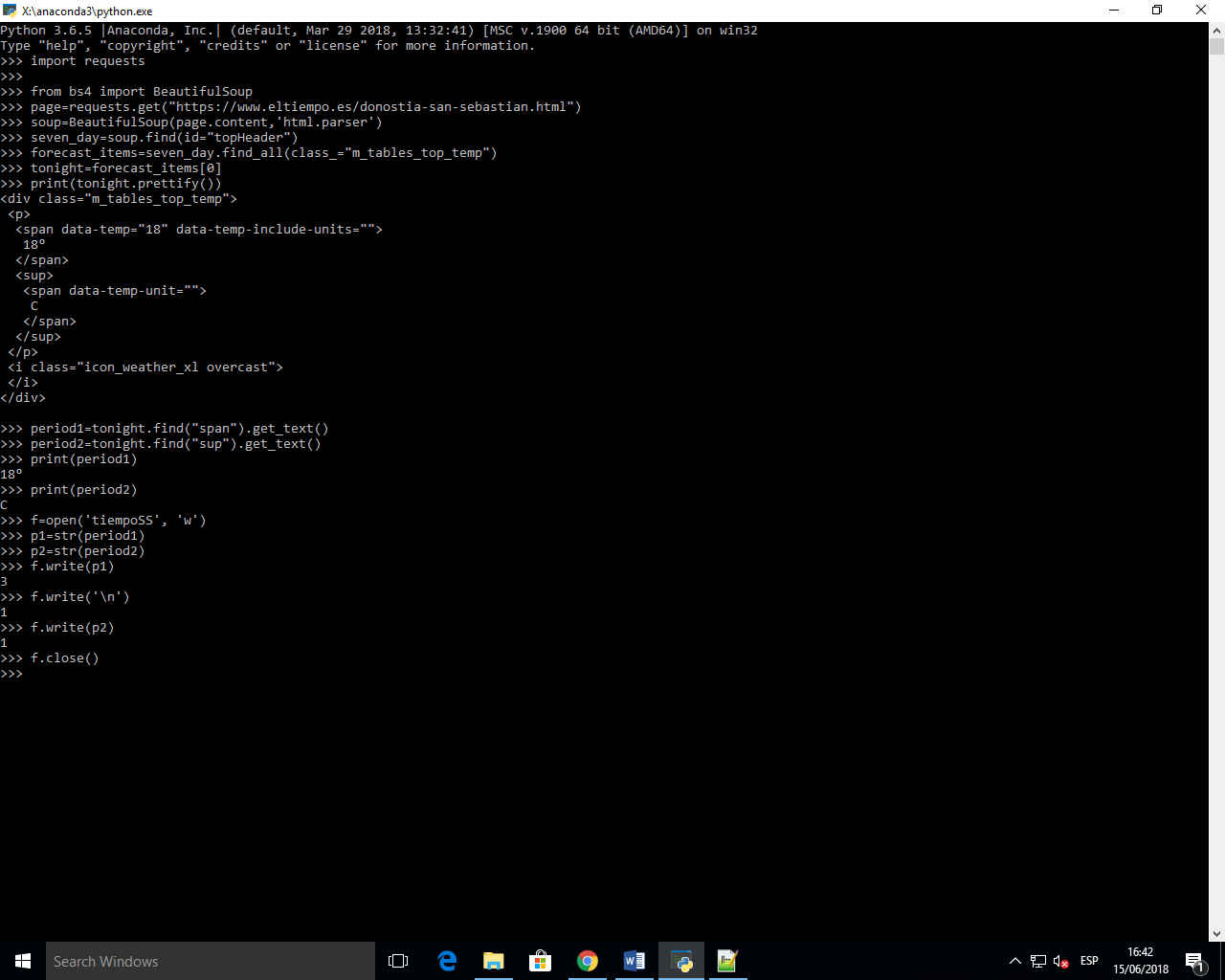
Se genera un documento TXT llamado tiempos.txt en la carpeta donde está guardado Python. Puede tardar unos minutos hasta estar completo. Después, abrir el documento tiempoSS con Notepad++:
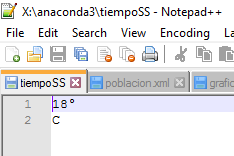
Se puede ver como el programa ha recogido los datos que se estaban buscando yendo a la web:
https://www.eltiempo.es/donostia-san-sebastian.html